Машинное обучение
1.Что такое переобучение?
Переобучение в машинном обучении происходит, когда ваша модель плохо обобщается. Модель слишком сосредоточена на тренировочном наборе. Он захватывает много деталей или даже шум в тренировочном наборе. Таким образом, он не может уловить общую тенденцию или отношения в данных. Если модель слишком сложна по сравнению с данными, она, вероятно, будет переподгонкой. Ярким показателем переобучения является большая разница между точностью обучающих и тестовых наборов. Модели переобучения обычно имеют очень высокую точность на тренировочном наборе, но точность теста обычно непредсказуема и намного ниже, чем точность обучения.
====================
- Как уменьшить переобучение?
Мы можем уменьшить переобучение, сделав модель более обобщенной, что означает, что она должна быть больше сосредоточена на общей тенденции, а не на конкретных деталях.
Если это возможно, сбор большего количества данных является эффективным способом уменьшения переобучения. Вы будете давать больше информации о модели, чтобы у нее было больше материала для изучения. Данные всегда ценны, особенно для моделей машинного обучения. Еще один способ уменьшить переобучение — уменьшить сложность модели. Если модель слишком сложна для данной задачи, это, скорее всего, приведет к переобучению. В таких случаях следует
искать более простые модели.
===================
3.Что такое регуляризация?
Мы упоминали, что основной причиной переобучения является более сложная модель, чем это необходимо. Регуляризация — это метод уменьшения сложности модели. Это достигается за счет штрафа за более высокие условия в модели. С добавлением члена регуляризации модель пытается минимизировать как потери, так и сложность.
Двумя основными типами регуляризации являются регуляризация L1 и L2. Регуляризация L1 вычитает небольшое количество из весов неинформативных признаков на каждой итерации. Таким образом, это приводит к тому, что эти веса в конечном итоге становятся равными нулю.
С другой стороны, регуляризация L2 удаляет небольшой процент из весов на каждой итерации. Эти веса будут приближаться к нулю, но на самом деле никогда не станут равными нулю.
===================
- В чем разница между классификацией и кластеризацией?
Оба являются задачами машинного обучения. Классификация — это задача обучения под наблюдением, поэтому мы пометили наблюдения (т. е. точки данных). Мы обучаем модель с помеченными данными и ожидаем, что она будет предсказывать метки новых данных.
Например, обнаружение спама в электронной почте является задачей классификации. Мы предоставляем модель с несколькими электронными письмами, помеченными как спам или не спам. После того, как модель будет обучена этим электронным письмам, она будет соответствующим образом оценивать новые электронные письма.
Кластеризация — это задача обучения без учителя, поэтому у наблюдений нет меток. Ожидается, что модель будет оценивать наблюдения и группировать их в кластеры. Подобные наблюдения помещаются в один и тот же кластер. В оптимальном случае наблюдения в одном кластере максимально близки друг к другу, а разные кластеры максимально удалены друг от друга. Примером задачи кластеризации может быть группировка клиентов на основе их покупательского поведения.
========
Пайтон
========
Встроенные структуры данных имеют решающее значение. Таким образом, вы должны быть знакомы с тем, что они из себя представляют и как с ними взаимодействовать.
Список, словарь, набор и кортеж — это 4 основные встроенные структуры данных в Python.
В чем разница между списками и кортежами
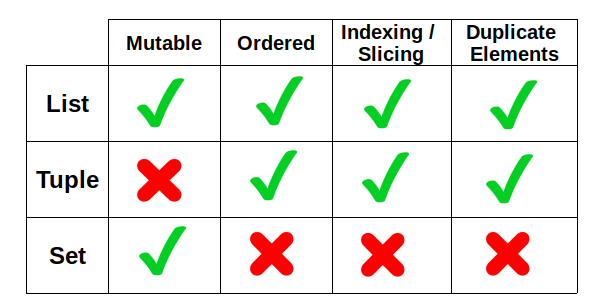
Основное различие между списками и кортежами заключается в изменчивости. Списки изменяемы, поэтому мы можем манипулировать ими, добавляя или удаляя элементы. С другой стороны, кортежи неизменяемы. Хотя мы можем получить доступ к каждому элементу кортежа, мы не можем изменить его содержимое. Здесь следует упомянуть один важный момент: хотя кортежи неизменяемы, они могут содержать изменяемые элементы, такие как списки или наборы.
В чем разница между списками и наборами
Вот таблица, в которой сведены основные характеристики списков, кортежей и наборов.
Что такое словарь и каковы важные особенности словарей?
В реальности меня часто спрашивали :-
Как создать DataFrame из словаря в Python-Pandas?
Преобразовать список словарей в pandas DataFrame
и быстро вспоминали об SQLITE Database.
Центр тяжести ( в моих интервью ) - экосистема Пайтон.
=========
SQL
=========
SQL — чрезвычайно важный навык для специалистов по данным. Есть довольно много компаний, которые хранят свои данные в реляционной базе данных. SQL — это то, что необходимо для взаимодействия с реляционными базами данных.Вам, вероятно, зададут вопрос, который включает в себя написание запроса для выполнения определенной задачи. Вам также могут задать вопрос об общих знаниях баз данных.
Что такое нормализация и денормализация в базе данных?
Эти термины связаны с проектированием схемы базы данных. Нормализация и денормализация направлены на оптимизацию различных показателей. Цель нормализации — уменьшить избыточность и несогласованность данных за счет увеличения количества таблиц. С другой стороны, денормализация направлена на ускорение выполнения запроса. Денормализация уменьшает количество таблиц, но в то же время добавляет некоторую избыточность.
Нормализация данных для DBA есть один и наиболее сложных этапов проектирования, так как его суть есть "tradeoff", стандартно решается уже на уровне тестовых прогонов на реальной БД.
2 эксперта согласны
Артём Бойко
27 мар 2022подтверждает
Как вариант.