Лучший
Разметка данных - это обработка неструктурированных с целью упрощения процесса обучения. Говоря простыми словами, люди выделяют необходимые объекты в кадрах или слова в текстах, чтобы машине было проще выявить закономерности.
Например, вы хотите сделать алгоритм, который будет размывать фон, но оставлять человека на переднем плане в фокусе. Для этого необходимо собрать тысячи фотографий и разделить на них всё по двум классам: человек и фон. Для более качественного результата здесь лучше всего подойдет семантическая сегментация.
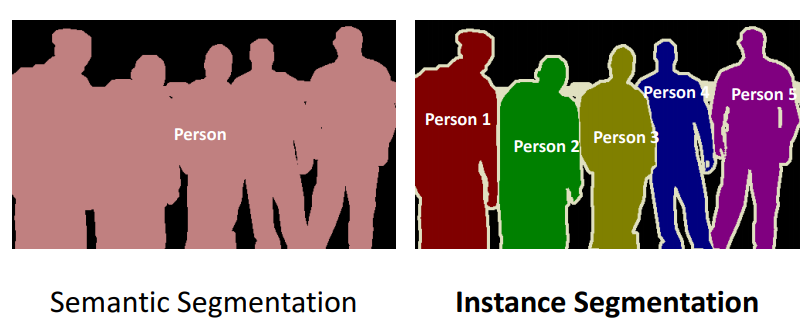
Семантическая сегментация - это создания цветовых масок по контуру объектов. То есть целая команда разметчиков выделяет человек и отдельно фон. Имея множество таких размеченных данных, нейросеть будет обучаться быстрее и точнее. Подробнее про виды сегментации можно почитать здесь.
Другой пример — извлечение именованных сущностей. Такая аннотация используется для создания и анализа текстовых файлов. Ее суть - научить нейросеть распознавать определенные категории слов: имена, адреса, время, даты и так далее. А разметчики в свою очередь берут необработанный текст и выделяют все эти категории в необработанном тексте.
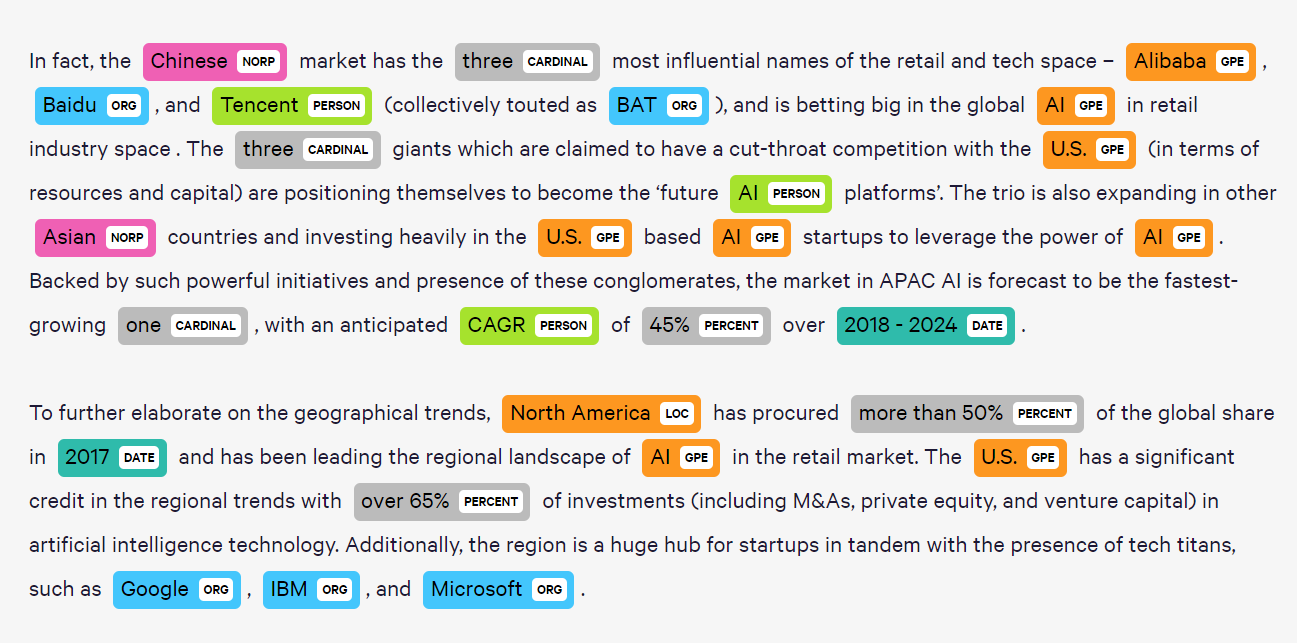
Для разных задач и целей используется своя разметка. Будь то компьютерное зрение или обработка естественного языка. Но суть остается неизменной: разметка данных позволяет машину перенять возможность человеческого восприятия, а местами и интерпретации.