MSA Transformer
MSA Transformer
Roshan Rao, Jason Liu, Robert Verkuil, Joshua Meier, John F. Canny, Pieter Abbeel, Tom Sercu, Alexander Rives
Статья: https://www.biorxiv.org/content/10.1101/2021.02.12.430858v1
Модель: https://github.com/facebookresearch/esm
Roshan Rao, Jason Liu, Robert Verkuil, Joshua Meier, John F. Canny, Pieter Abbeel, Tom Sercu, Alexander Rives
Статья: https://www.biorxiv.org/content/10.1101/2021.02.12.430858v1
Модель: https://github.com/facebookresearch/esm
Продолжим тему про DL в биологии. Этот пост является логическим продолжением и развитием работ из https://t.me/gonzo_ML/609 и https://t.me/gonzo_ML/621 от той же команды.
В предыдущих работах на последовательностях одиночных белков (но в гигантском количестве) обучили языковую модель в стиле BERT (на Masked Language Modeling задаче, когда маскируются отдельные токены входа и модель должна восстановить их на выходе) и показали, что модель выучивает интересные и полезные для других задач фичи. Всё как в NLP в общем.
Но в биологии есть более богатый подход (что, кстати, могло бы быть его аналогом в NLP?) — работать не на одиночных последовательностях, а на множественных выравниваниях (Multiple sequence alignment, MSA), когда к последовательности добавляется множество её эволюционных родственников, которые все выровнены по позициям. На таком выравнивании сразу видно, где произошли замены аминокислот в белке и какие позиции в белке более консервативны (а значит и более важны), и где были вставки и делеции. Посмотреть примеры и подробнее почитать про MSA можно в Википедии https://en.wikipedia.org/wiki/Multiple_sequence_alignment.
При обучении на большом датасете одиночных последовательностей сеть неявно всё равно вытягивает это знание, но оно оказывается зашито внутрь сети. Альтернативно можно сделать этот процесс более явным, подавая выравнивание на вход, тогда и сети вроде как не надо всё это выучивать, а можно извлекать из входных данных, что по идее проще и потребует меньше параметров (spoiler: в реальности обученная в работе сеть использует микс обоих вариантов).
Встречайте MSA Transformer — трансформер, работающий на множественных выравниваниях.
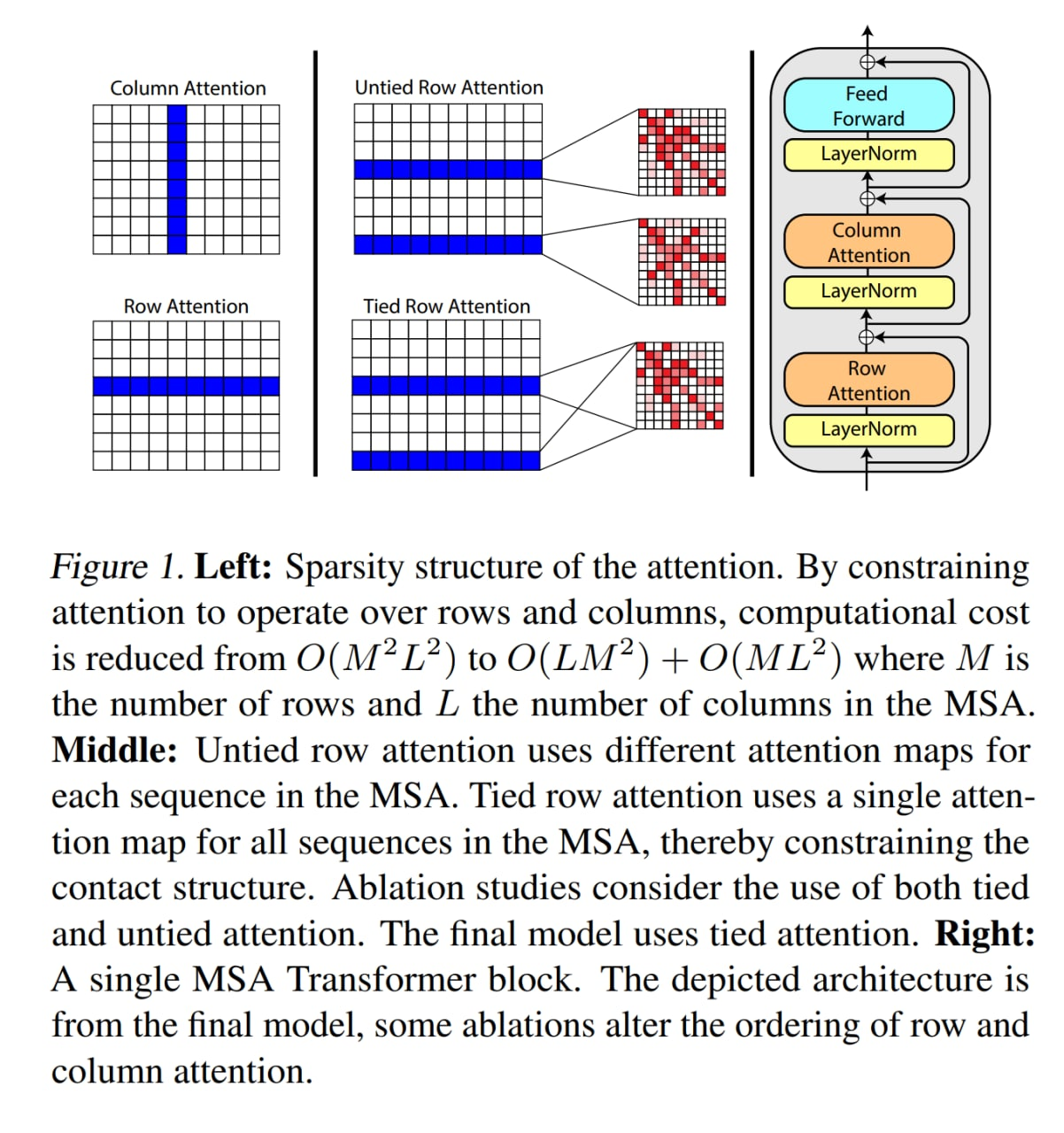
Вход теперь, в отличие от обычного трансформера, получается двумерным и в модели чередуются блоки внимания по строкам и по столбцам. Это по сути практически архитектура Axial Transformer, мы про неё подробно не писали, но упоминали в разных местах (в посте про картиночный трансформер https://t.me/gonzo_ML/434 и в слайдах про разные трансформеры https://youtu.be/KZ9NXYcXVBY?t=3082 и https://youtu.be/7e4LxIVENZA?t=976).
Если делать это на обычном трансформере, растягивая MSA в одномерную последовательность, то будет слишком дорого, получится сложность O(M^2*L^2), где M — число последовательностей, а L — длина выравнивания. А так выходит O(ML^2) для блоков внимания по строкам и O(LM^2) для внимания по столбцам. Этот вариант трансформера ещё и шарит карту внимания между всеми строками, так что для строк получается даже O(L^2).
Есть ещё мелкие изменения по части нормализации и расположения полносвязных слоёв.
Задача обучения всё та же — MLM. Модель пытается восстановить повреждённую MSA. То есть всё тот же self-supervised learning.
Обучают трансформер на 100М параметров (скромно на фоне ESM-1b, который был на 650М и содержал 34 слоя; здесь всего 12 слоёв) на большом (4.3 Тб) датасете в 26М множественных выравниваний. Отдельное выравнивание генерится для для каждой последовательности из UniRef50 поиском в UniClust30 с помощью HHblits. Средняя глубина MSA получается 1192.
При инференсе пробовали считать не на полном MSA, а на подвыборке с разными стратегиями сабсемплинга.
Результаты?
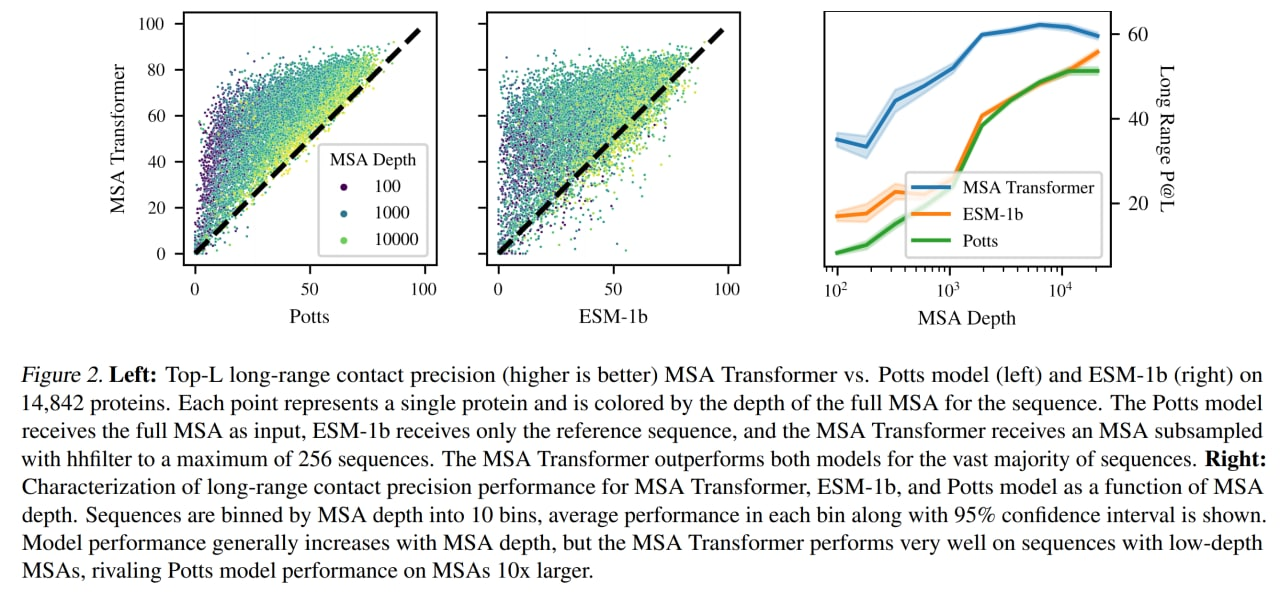
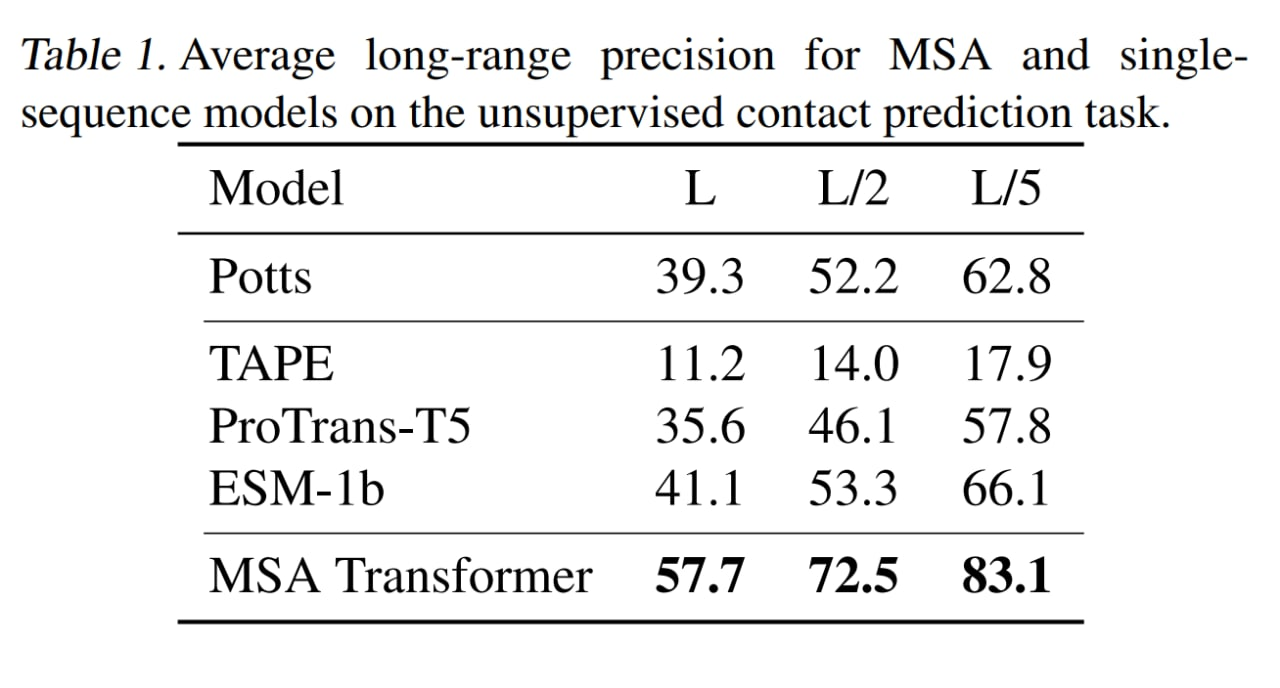
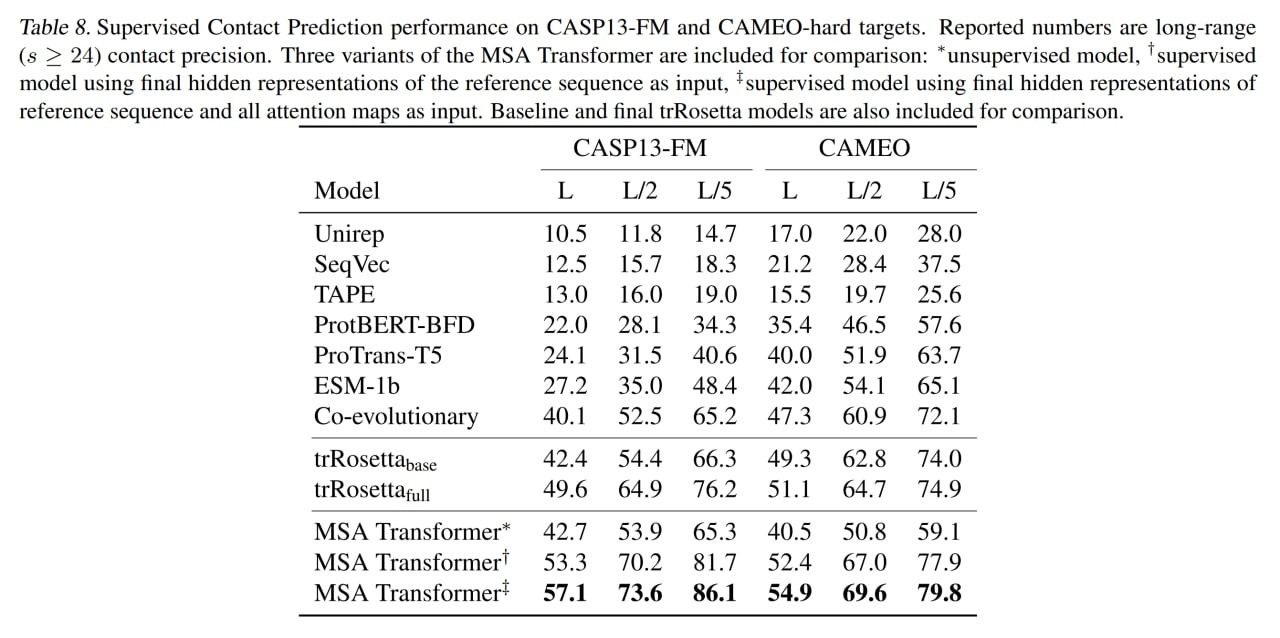
На задаче unsupervised contact prediction сравниваются с ESM-1b (650M параметров) и ProTrans-T5 (3B, видимо ProtT5-XL, про него как-нибудь отдельно), а также с Potts model. Используют методику из предыдущей статьи, где с помощью разреженной логрегрессии определяли головы внимания, хорошо справляющиеся с данной задачей. При инференсе делали подвыборку в 256 последовательностей с помощью hhfilter.
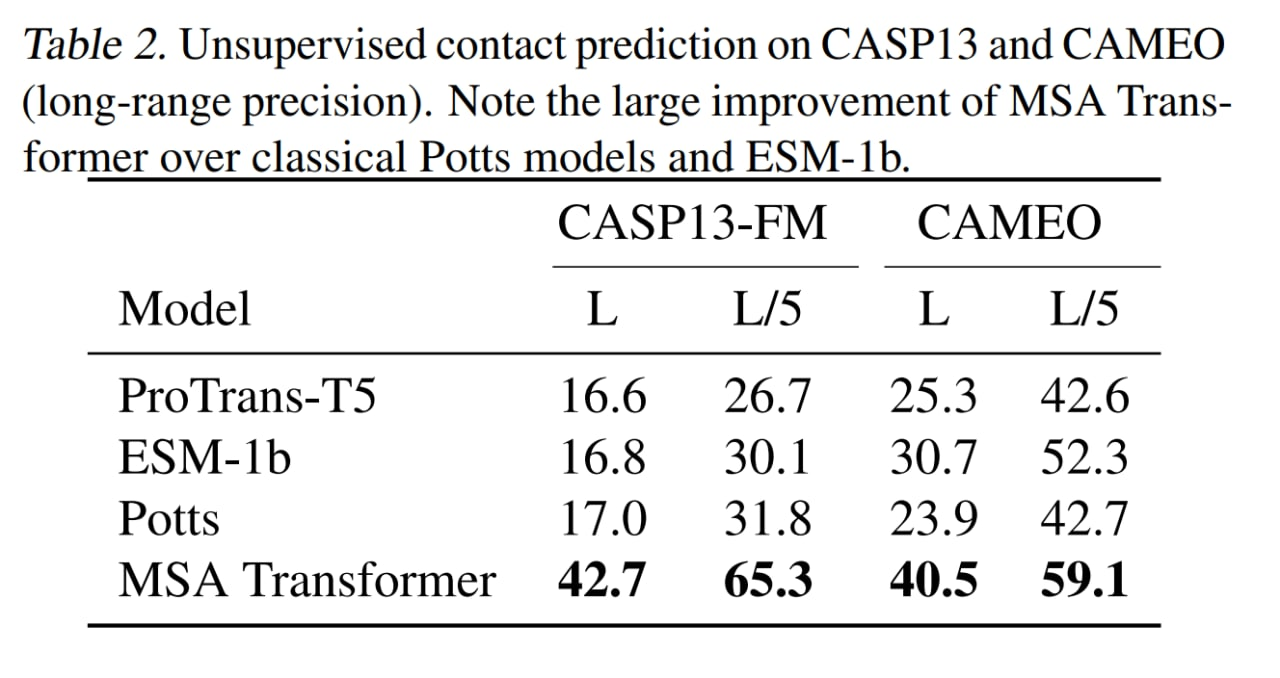
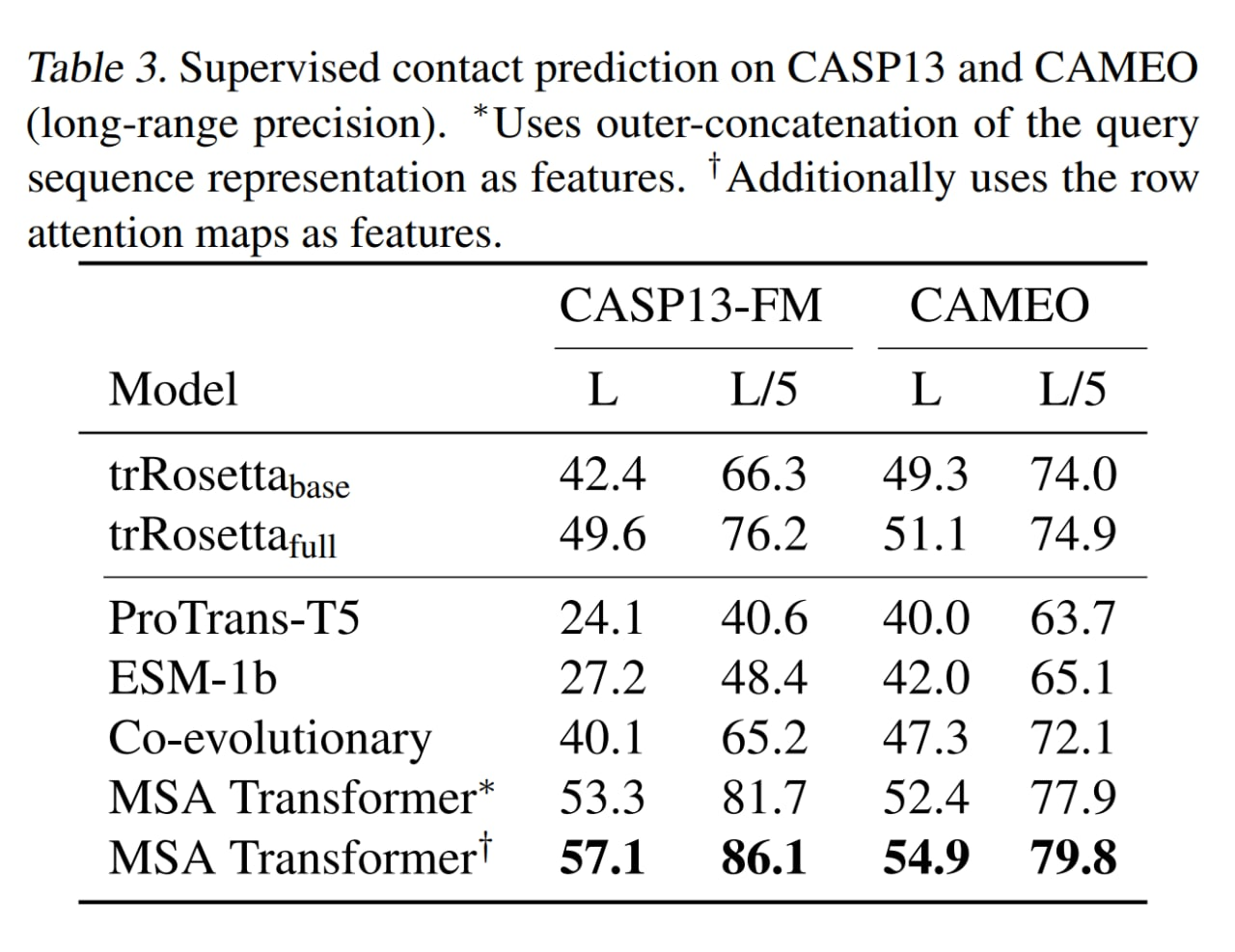
MSA трансформер побил все бейзлайны (и ESM-1b побил ProTrans-T5). Также сравнились на CAMEO hard targets и CASP13-FM, на последнем сравнимо с supervised trRosetta_base.
На supervised contact prediction (на фичах MSA transformer обучают resnet) побили в том числе более качественную trRosetta_full.
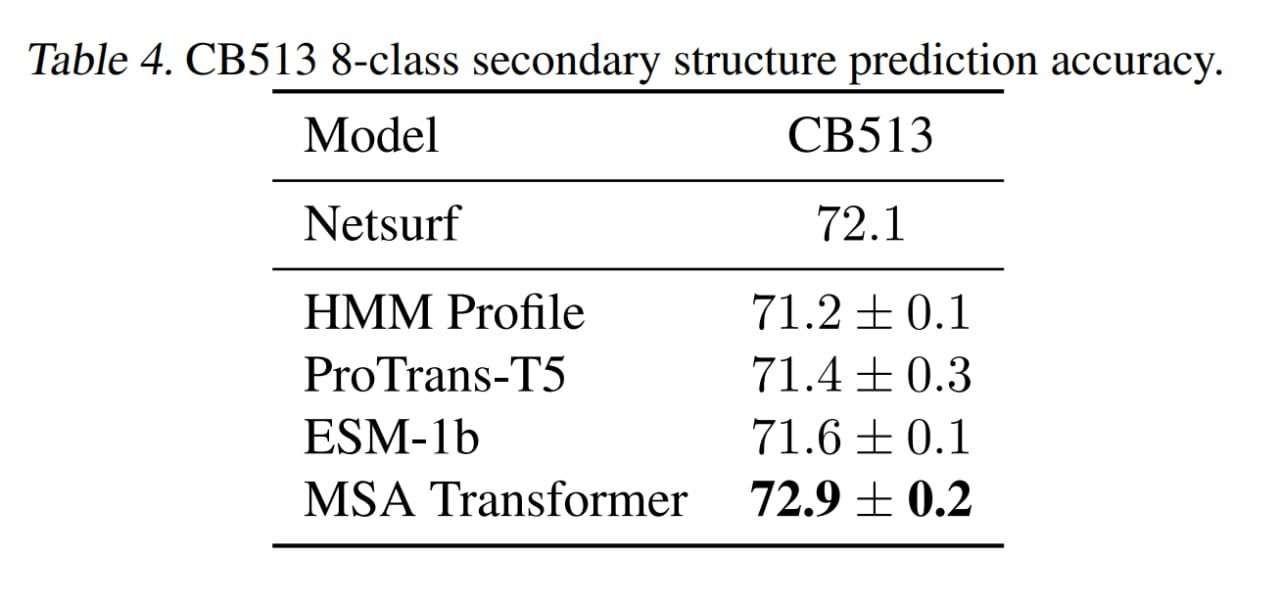
Проверились на задаче предсказания вторичной структуры на CB513, обошли профили HMM, ESM-1b и Netsurf.
Поэкспериментировали с разнообразием последовательностей в MSA. Стратегии, максимизирующие разнообразие, дают качество выше ESM-1b с всего 16 последовательностями на входе. И добавление всего одной последовательности в высоким diversity перекрывает 31 последовательность с низким.
Головы внимания к строкам любят столбцы с высокой изменчивостью. А внимание по столбцам больше смотрит на более информативные последовательности. Также логрегрессия нашла 55 (из 144) голов, предсказывающих контакты.
Такие дела. Скейлить по идее есть куда, ждём продолжения.


Оригинал: https://t.me/gonzo_ML/631
Машинное обучение+2
ОЧЕНЬ ЛЮБОПЫТНО. ОБЪЯСНИТЕ НА РУССКОМ ЯЗЫКЕ ДЛЯ ЧАЙНИКОВ. СПАСИБО.